
How to apply hexagonal architecture to Rust
For all of you Rust-lovers out there, we have a treat for you: let’s walk through the steps of applying hexagonal architecture to Rust so you can adopt this approach to your robust projects as well.
Hexagonal architecture, also known as the ports and adapters architecture, was originally designed to mitigate some of the shortcomings of OOP (Object-Oriented Programming) languages by providing a framework for building decoupled applications. The architecture focuses on creating modular and interchangeable system components by constraining them to communicate solely through interfaces (ports) while keeping the implementation details encapsulated in dedicated components (adapters).
One of its key features is that it favors composition over inheritance to avoid inheritance spaghetti, i.e. unexpected coupling of system components. This is almost a match (pun intended) made in heaven - Rust does not support inheritance and its trait system is modular by design. Combining this approach with a language like Rust allows us to build extremely resilient systems due to how Rust works internally - say goodbye to runtime exceptions and panic (unless you unwrap, in which case: shame on you)!
This blog will cover a rustic spin on hexagonal architecture. Onion architecture also consists of very similar principles. Even though they were originally designed for OOP systems, we'll see that they can be easily applied to Rust with the added benefit of costless abstractions, i.e., compile-time polymorphism.
A picture says a thousand words - a JPEG probably says less, but you get the idea
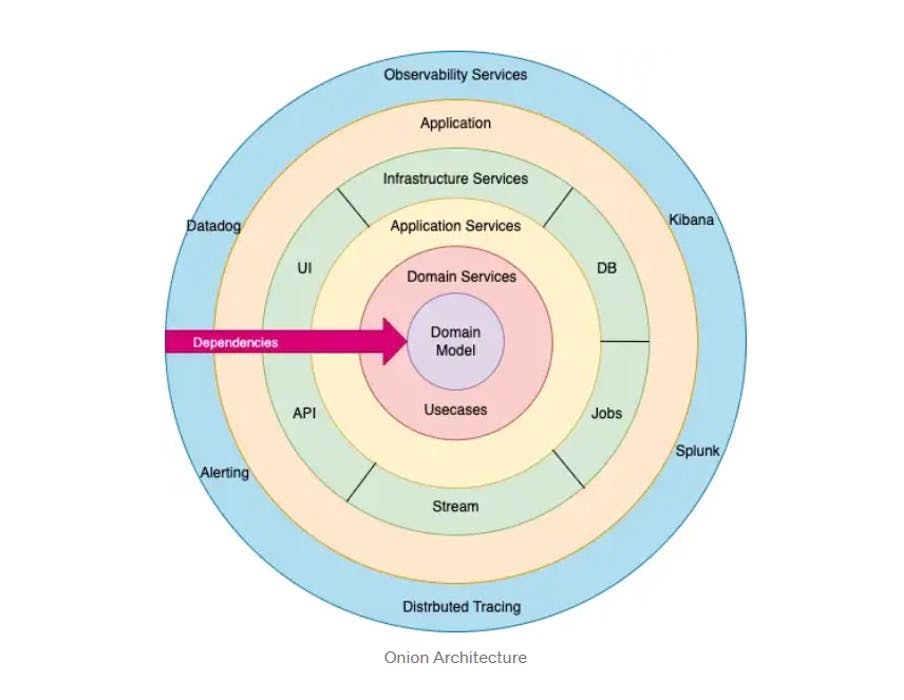
Onion architectures
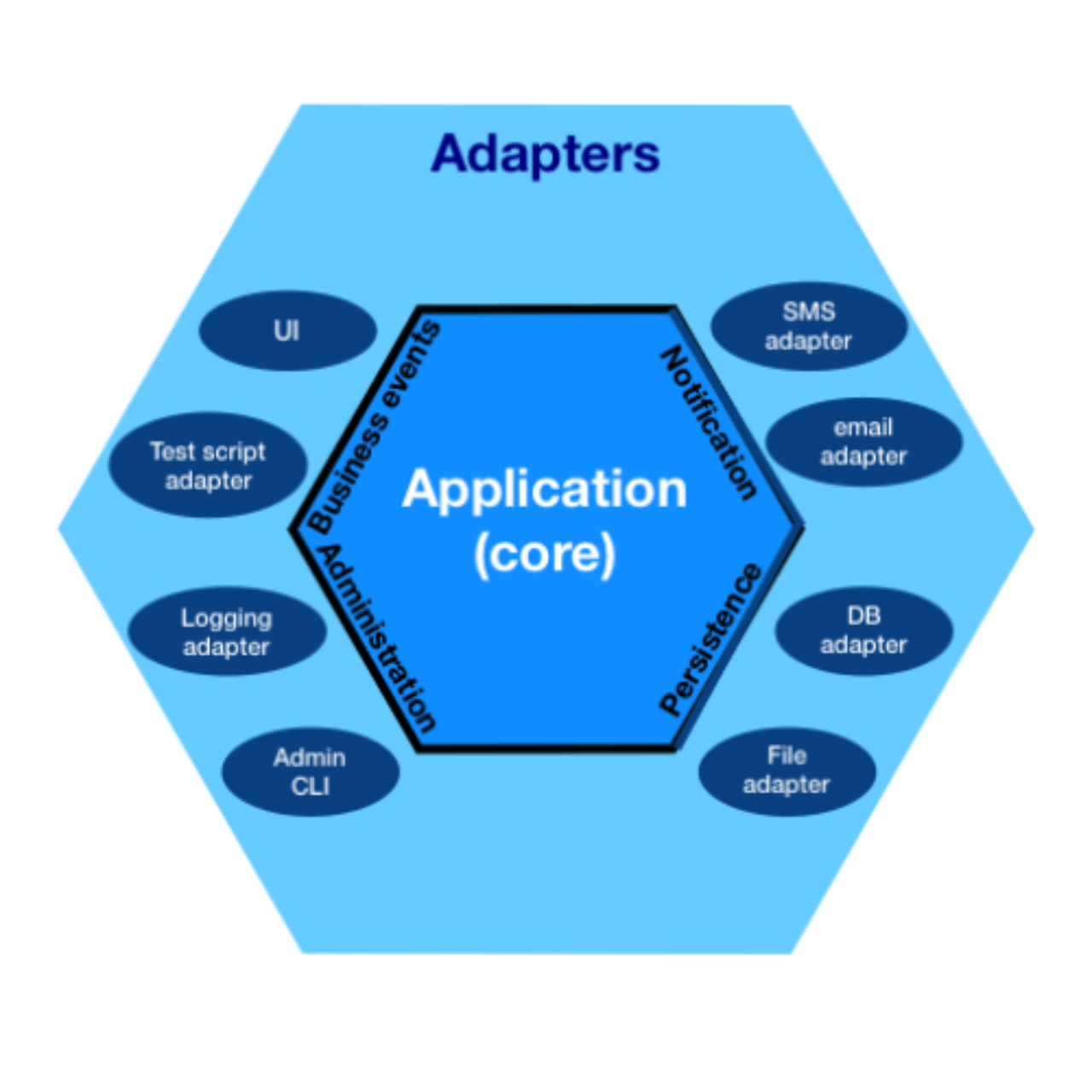
Hexagonal architectures
The above images show the onion and hexagonal architectures, respectively. They are slightly different, but you can see the important similarities between them - the application core is always in the middle and the dependencies are pointing inward. This shines light on an important goal we aim to achieve - properly layering the software and defining the boundaries between its components.
In both of them a few key points stand out:
Concrete units are isolated to their own classes (adapters) while the application core uses interfaces (ports) to communicate with them. The application core has no idea of the underlying adapter implementations. Subsequently, the core is coupled only to the interfaces its components expose and never the implementation.
By design, it is polymorphic as we only have to create an adapter that implements that interface and plug it in on startup while the core business logic always remains the same.
This approach makes sure we only ever need to change the outer layers if we want to change our implementations. Core logic is only ever touched if the requirements change.
Going forward, we will focus on structuring the core business layer of our app. This makes the methods through which our core communicates with the outside world, as well as the underlying data source implementations, irrelevant. This is completely arbitrary and will largely depend on the requirements for the project. The beauty of this architecture is that it allows us to disregard the how and focus solely on the what, as you will later see.
Time to get Rust-y
I will omit Rust's boilerplate when it comes to async traits, mockall, and all the tidbits to make the code compile, as it can get pretty elaborate. I will write all the implementation as though everything was synced, disregarding lifetimes that would probably be necessary if we were actually trying to compile the code but keep in mind the concepts are fully compatible with async rust. Working examples can be found here.
For the concrete implementations, I will be using Postgres with Diesel and Actix_web for the data source and interactor, respectively.
Let's imagine we have a simple authentication service and we associate a login function with it:
// Input
#[derive(Debug, Deserialize)]
struct Login {
pub email: String,
pub password: String,
}
// Output
#[derive(Debug, Serialize)]
struct Session {
id: String,
user_id: String
}
// Represents the application wide error enum
enum Error {
/* ... */
}
pub struct AuthenticationService;
impl AuthenticationService {
fn login(&self, data: Login) -> Result<Session, Error> {
/* ... */
}
}
Since we want to keep our interactors decoupled from the service, we need to create a layer that defines only our desired behavior. In OOP, we use interfaces, while in Rust, we use traits:
trait AuthenticationContract {
fn login(&self, data: Login) -> Result<Session, Error>;
}
An interactor is a chunk of code that calls the methods on the service and propagates the result to whatever invoked the interactor. Interactors are entry points to services and they can be written to support various kinds of protocols, depending on the application. The following HTTP handler is an interactor:
async fn handle_login<T>(
service: web::Data<T>
login: web::Json<Login>
) -> Result<impl Responder, Error>
where
T: AuthenticationContract
{
let login_data = login.0;
let session = service.login(login_data)?;
HttpResponseBuilder::new(StatusCode::OK).json(session)
}
- The service parameter is any type wrapped in Actix's Data, which is essentially a pointer to T. T can be of any type as long as it implements the AuthenticationContract trait, denoted by the where T: Authentication Contract.
- The login parameter is a JSON request body. Json is a named tuple structure containing a deserialized form of our Login data. To be concise, we will not perform any validation, but we would in a production scenario.
- Responder is an actix trait used to indicate any type that can be turned into an HTTP response. With this function signature, we can return any type as long as it implements Responder.
- We are returning an HttpResponse struct that conveniently implements Responder with a Session struct as a JSON body obtained from calling the service.
The key thing to note here is that there are no service implementation details in this handler. The only way we get access to the login function is through the bound T: AuthenticationContract. In this way, we are never coupling the handler to a specific struct, but instead, we are only specifying the API we want from the service parameter. This pattern will occur in almost every aspect of our system.
In order to call the handler with our auth service, the service struct must implement AuthenticationContract:
impl AuthenticationContract for AuthenticationService {
fn login(&self, data: Login) -> Result<Session, Error> {
todo!()
}
}With this implementation, we can concretize the T in the handler to AuthenticationService when we register it as a route handler in the application.
When defining our login function, our goal is to hide the implementation details of data sources from the business layer, i.e., the AuthenticationService. By doing so, we ensure our business layer is decoupled from any underlying implementations. The way we achieve this is through generics and trait bounds:
pub struct AuthenticationService<R> {
repo: R
}
impl<R> AuthenticationService<R>
where
R: AuthRepositoryContract
{
pub fn new(repo: R) -> Self {
Self { repo }
}
}
impl<R> AuthenticationContract for AuthenticationService<R>
where
R: AuthRepositoryContract
{
fn login(&self, data: Login) -> Result<Session, Error> {
let user = self.repo.get_user_by_email(&data.email)?;
validate_password(&user.password, &data.password)?; // Not relevant for this, but it is a login function after all
self.repo.insert_session(&user)
}
}
pub trait AuthRepositoryContract {
fn get_user_by_email(&self, email: &str) -> Result<User, Error>;
fn insert_session(&self, user: &User) -> Result<Session, Error>;
}
This struct definition uses an opaque R type to represent something that will ultimately be a data source. We constrain the struct to our desired behavior in the trait implementation. This way, our business layer relies solely on the API exposed with AuthRepositoryContract and does not care which concrete type will be.
In order for this to work, we have to define a struct that will implement AuthRepositoryContract, but we must first take a detour on how our data sources will be set up.
Data sources consist of repositories, traits that provide access to application models, whose concrete instances are created through adapters.
Data sources will usually need some kind of connection to manipulate data. This connection will vary based on the data source, so in order to create a normalized API, we need a way to abstract it away from our core's logic.
For this, we use a generic C parameter in the repository representing a connection:
// The `User` model is completely arbitrary, but for completeness we give its definition
pub struct User {
id: Uuid,
email: String,
password: String,
}
pub trait UserRepository<C> {
fn get_by_email(conn: &mut C, email: &str) -> Result<User, Error>;
}
Now we must define an adapter. You can think of adapters as data access objects - in Rust, they are structures that implement repository traits with their own concrete connections. For example, we can use Diesel:
#[derive(Debug)]
pub struct UserAdapter;
impl UserRepository<PgConnection> for UserAdapter {
fn get_by_email(conn: &mut PgConnection, email: &str) -> Result<User, Error> {
use crate::schema::users::dsl;
dsl::users
.filter(dsl::email.eq(email))
.first(conn)
.map_err(Error::from)
}
}
The key here is to always make service components that access data sources depend on the repositories as this ensures concrete implementations never reach the business layer.
We need the struct here in order to implement the trait on something. We can see the struct is zero-sized, which means it will not actually allocate any memory. Similarly, we will later see our components will use PhantomData, which also does not allocate any memory. This makes our services very lightweight since all their components contain a single pointer to connection pools.
Since repository methods take in a connection (we will explain why in a moment), service components must be able to establish one. This introduces the need to unify repository connections into a single API to decouple the components from the implementations.
Since service components cannot know in advance which connection will be used, we must define an abstraction around establishing connections:
pub trait Connect {
type Connection;
fn connect(&self) -> Result<Self::Connection, Error>;
}
And we must implement this abstraction on our concrete implementations in order to make them injectable:
pub struct PostgresPool {
pool: Pool<ConnectionManager<PgConnection>>,
}
impl Connect for PostgresPool {
type Connection = PgConnection;
fn connect(&self) -> Result<Self::Connection, Error> {
self.pool.get().map_err(Error:from)
}
}
Now that we have an idea of what our data sources look like, it's time to define the service component that will interact with them:
pub struct AuthRepository<D, C, User, Session>
where
D: Connect<Connection = C>,
User: UserRepository<C>,
Session: SessionRepository<C>
{
driver: Arc<D>,
_user: PhantomData<User>,
_session: PhantomData<Session> // Follows the same principles as UserRepository
}
The driver field of the structure is the one responsible for establishing connections. Looking at the bounds, we can see D has to implement Connect, which allows us to establish the connection C with it. We can also see that User is bound to UserRepository<C>, which gives us access to the repository's methods whose signatures will contain the connection C.
One thing to note from the repository is that it does not take in a &self parameter, which means putting it in the struct's fields makes no sense. However, if we do not put it in the struct, Rust will complain we have unused generic parameters. We get around this by putting repository bounds in PhantomData. If we were to remove the fields from the structure, the User and Session parameters in the AuthRepositoryContract implementation would not be constrained by anything and would not compile.
impl<D, C, User, Session> AuthRepositoryContract for AuthRepository<D, C, User, Session>
where
D: Connect<Connection = C>,
User: UserRepository<C>,
Session: SessionRepository<C>
{
fn get_user_by_email(&self, email: &str) -> Result<User, Error> {
let mut conn = self.driver.connect()?;
User::get_by_email(&mut conn, email)
}
fn insert_session(&self, user: &User) -> Result<Session, Error> {
let mut conn = self.driver.connect()?;
// Use power of imagination
Session::insert(&mut conn, user)
}
}
impl<D, C, User, Session> AuthRepository<D, C, User, Session>
where
D: Connect<Connection = C>,
User: UserRepository<C>,
Session: SessionRepository<C>
{
pub fn new(driver: Arc<D>) -> Self {
Self {
driver,
_user: PhantomData,
_session: PhantomData
}
}
}
With this implementation we now have everything we need to set up the service in our application. In order to keep our code a bit cleaner, we will create a type for a concrete instance of AuthRepository using the PostgresPool and the adapters we created:
pub type AuthenticationRepository = AuthRepository<PostgresPool, PgConnection, UserAdapter, SessionAdapter>;
We can now create an instance of AuthenticationService:
pub struct AppState {
pub db_pool: Arc<PostgresPool>
}
fn setup_services(state: &AppState, /* interactor specific params */) {
let auth_service = AuthenticationService::new(AuthenticationRepository::new(state.db_pool.clone()));
/* connect the service to an interactor */
}
We can see AuthenticationService's R parameter is bound only to AuthRepositoryContract. AuthenticationRepository satisfies these bounds as it is just a concrete instance of AuthRepository using PostgresPool.
Likewise, AuthenticationRepository can be constructed because we have implemented the Connect trait for PostgresPool.
Additionally, UserAdapter and SessionAdapter both satisfy the UserRepository and SessionRepository bounds, respectively, using PgConnection as their connection. This is important because we have stated that we want those repositories to use C as their connection, and we can see that the C parameter is concretized to PgConnection in AuthenticationRepository. If these parameters mismatch or any of the adapters do not implement the Repository trait with PgConnection, this will not work.
A note on repositories and transactions
You might be wondering why service components would need to establish repository connections since they are so close to the business layer. The simple reason for this is transactions. Most ORMs (Object-Relational Mapping) allow you to start and end transactions on their connections, and we need to keep that ability close to the business layer. Service level repository components could utilize multiple repositories at once (e.g., our auth service needs to have access to our user and session repositories at once), and there could exist the need for atomicity since we don't want to leave our persistence in an incomplete state in case an error occurs or our logic demands it. Because of this, the business layer has to be able to perform atomic queries. Since we have abstracted the connection from the business layer, we cannot use any concrete transaction manager. Instead, we need to create an abstraction around executing transactions:
pub trait Atomic {
type TransactionResult;
fn start_tx(self) -> Result<Self::TransactionResult, Error>;
fn abort_tx(tx: Self::TransactionResult) -> Result<(), Error>;
fn commit_tx(tx: Self::TransactionResult) -> Result<(), Error>;
}
The need for this trait arises because of the distinctions in how transactions are manipulated in different ORMs - some will start the transaction in place on the connection, others will return a completely new struct representing a transaction (e.g. Diesel and MongoDB start it in place, sea_orm uses a transaction struct). In order to normalise the API our business layer uses, we need this layer of indirection, otherwise there would be no feasible way to perform transactions without changing the business logic.
We now modify the get_user_by_email function of our AuthRepository to be atomic (solely for the sake of giving an example):
impl<D, C, User, Session> AuthRepositoryContract for AuthRepository<D, C, User, Session>
where
C: Atomic, // Extra bound for the connection
D: Connect<Connection = C>,
// User repo now need to operate on both the C and its tx result
User: UserRepository<C> + UserRepository<<C as Atomic>::TransactionResult>,
Session: SessionRepository<C>
{
fn get_user_by_email(&self, email: &str) -> Result<User, Error> {
let mut conn = self.driver.connect()?;
let mut conn = conn.start_tx()?;
match User::get_by_email(&mut conn, email) {
Ok(user) => {
conn.commit_tx()?;
Ok(user)
}
Err(e) => {
conn.abort_tx()?;
Err(e)
}
}
}
}
With this design, our service components can perform atomic queries, but they still have no idea which connection or adapter they will use, so they remain decoupled. This is very important for our API since we do not want to change the business layer when switching up our adapters.
Our UserAdapter, as well as the PgConnection, do not satisfy AuthRepository's bounds anymore, so we need to fix that. In the case of our diesel adapter, this is a very simple addition:
impl Atomic for PgConnection {
type TransactionResult = Self;
fn start_tx(mut self) -> Result<Self::TransactionResult, Error> {
diesel::connection::AnsiTransactionManager::begin_transaction(&mut self)?;
Ok(self)
}
fn abort_tx(tx: Self::TransactionResult) -> Result<(), Error> {
diesel::connection::AnsiTransactionManager::rollback_transaction(&mut tx)?;
Ok(())
}
fn commit_tx(tx: Self::TransactionResult) -> Result<(), Error> {
diesel::connection::AnsiTransactionManager::commit_transaction(&mut tx)?;
Ok(())
}
}
The bounds are now satisfied because PgConnection, which, as we know in our example, ultimately substitutes C, implements Atomic. The UserRepository<<C as Atomic>::TransactionResult> bound is also satisfied because our Atomic::TransactionResult for PgConnection is the connection itself. We can see the UserAdapter already implements the repository with it as the connection (usually, a transaction struct will implement some sort of trait that will allow us to design our repositories in terms of the trait instead of concrete structures).
Without this indirection, it would be unfeasible to perform an atomic query across multiple repositories.
Another potential solution would be to place the connection pools (drivers) directly in the adapter and make the adapter worry about performing transactions. This would make our service components much simpler, and they would not need all those crazy generics. With this approach, however, we would have to create an adapter for each of our service components and we would not be able to reuse them as they would be very specific to the service they belong to. Additionally, it is generally advised to keep this capability in the client (our auth service) as it has the necessary context to execute transactions.
It is worth noting that there is no silver bullet: for example, cache access adapters could very well contain a pointer to connection pools themselves if they are general enough that they can be used throughout the whole application since these adapters usually do not require atomicity. If you do not need transaction management in your business logic, feel free to experiment and find a solution that suits the problem best!
My blog has a diagram, which means I know what I’m talking about
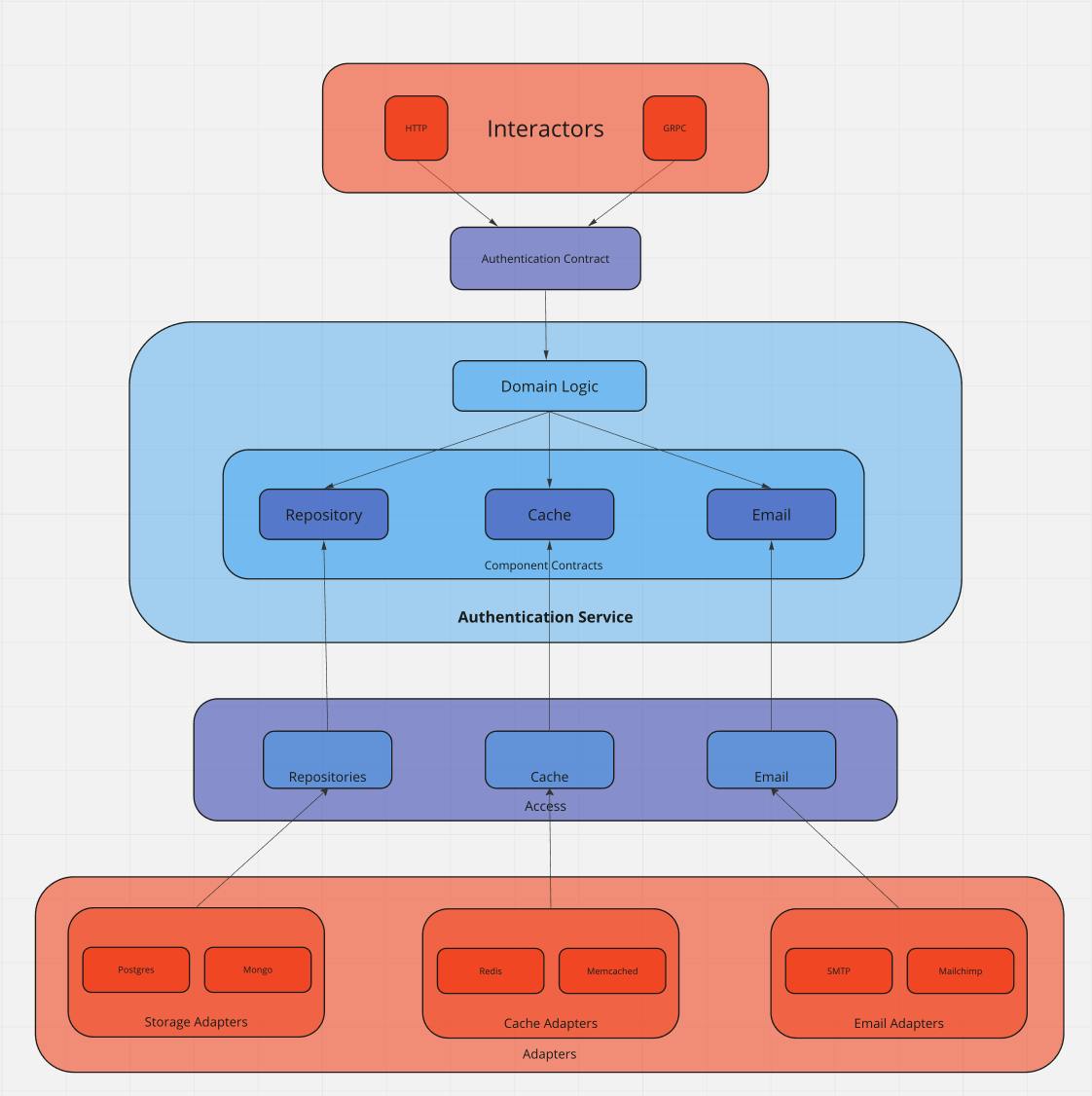
In this post, we've pretty much covered, from top to bottom, the left side of this image. The image is also analogous to the previous two, where our core would be components colored in blue, and our peripherals would be those colored in red.
The top layer contains the interactors; We've built an interactor using the actix_web framework. We didn't show how to hook the interactor up to our app because it is pretty straightforward and is located in the example.
The second layer is the contract we demand from our service - it provides us with a layer of abstraction we can use in our handlers to never specify a concrete service in them.
The cache and email components would follow the same design pattern as the repository; Their APIs would be exposed to the service via component contracts, and we would restrict the service's AuthenticationContract implementation to only be valid when those contracts are fulfilled.
The core layer (Authentication service) consists of its domain logic, which is the code that performs the business, and it is bound to the service component contracts (in the example image, there are 3). These contracts allow us to abstract away the implementation details from the core and write our business layer in terms of behavior without ever knowing the concrete implementations below.
The access layer specifies the behavior of our system-wide components, such as the persistence, caching, and email layers. Any service components we specify will ultimately rely on this layer. Because of this, the layer contains no implementation details, it is simply providing an interface that the components can use to get access to the system-specific resources.
Finally, we have our adapters - concrete implementations of specific functionalities we require for the application to work.
Notice how our concrete implementations (red) never directly touch our core (blue). Instead, their functionality is linked to the core via indirections (purple). This is very important. If we were to short-circuit either of these relations, we would inevitably couple our core to implementation details of either the handlers or the adapters.
So many contracts, it feels like I’m buying real estate
The amount of contracts we will have in our services may seem excessive, but they are there for two main reasons;
The first is to create simpler bounds on the AuthenticationService. We could have placed all the bounds from the AuthRepository directly on our service, which would mitigate the need for an extra struct. However, with that approach, the bounds on our AuthenticationService would get out of control really fast. It might not be obvious from the example, but in the real world, our service might need to access the cache and notify users via email. With this approach, we would need generics for the database connection and its access trait, the cache connection and its access trait, and so on. By dividing our service functionality into its components, we are destructuring it to make it readable and more manageable.
The second and arguably the more important one is that these traits provide the signatures for our behavior, and through the use of mockall, we can create unit tests in a breeze. If we did not have the contracts, we would have to write all our test structures manually. Through the use of mockall::automock this is done automatically, and we can simply start writing our tests with everything pre-mocked, which is a great time saver.
It is worth noting most of our component contracts will be one-of traits, and we could create a procedural macro to generate them automatically (this approach is used in hextacy).
Conclusion
We've seen how we can utilize Rust's type system, namely traits and generics, to create layers of indirection in our system to ensure its modularity. By designing our system this way, we've ensured the core business logic of our application remains decoupled from any concrete implementations.
This design enables us to efficiently unit test our application since it allows our services to be written in terms of their behavior through traits, and this allows us to effectively mock our service and its components.
The key is to never introduce dependencies that will force us to change our core logic, i.e., properly layering the system and selectively exposing APIs between the layers to ensure changes in one do not affect another.
The architecture described in this post is intended for robust projects that require long-term maintenance, so if you're building something of a smaller scale, this type of development will introduce unnecessary expenses - always analyze and try to find the correct architecture for the job!
Hey, you! What do you think?
They say knowledge has power only if you pass it on - we hope our blog post gave you valuable insight.
If you want to share your own opinion, or need some help in applying hexagonal style to your Rust, feel free to contact us.
We'd love to hear what you have to say!