
How to build a cost-effective Kubernetes disaster recovery plan
Every business relies on documents, applications, and data to function and losing some of them can have serious consequences. Since the IT world can be quite unpredictable, Disaster Recovery plan is insurance that a business will be up and running as soon as possible.
Planning ahead is key to success
Disaster recovery (DR) involves a set of policies, tools, and procedures that allows us to resume normal operation following a disaster by regaining access to data, hardware, software, network, and other crucial parts of our business.
One of the most important things when talking about Disaster recovery is RTO (Recovery time objective). RTO is defined as the amount of time it takes for your organization’s infrastructure to come back online and be fully functional in case of a natural or human-induced disaster.
Disaster Recovery and Business Continuity are close terms but not the same. Business continuity is an organization's ability to ensure operations and core business functions are not severely impacted by a disaster or unplanned incident that takes critical systems offline, whereas Disaster Recovery is all about getting your infrastructure and operations up and running again.
In this context, we can say that disaster is any unforeseen event that can significantly put your organization at risk by interfering with your daily operations. Of course, not every disaster has to involve a catastrophic destruction scenario, but in order to run a stable and consistent business, it is better to be safe than sorry.
Why is an efficient Disaster Recovery plan necessary?
Although most companies tend to the safety of their data, they are more often concerned about data leakage rather than what would happen if all the crucial information suddenly became inaccessible. Natural or human-induced, disasters can happen, and it would be wise for all companies to prepare ahead for such eventualities.
Our organization started to grow and the number of clients increased, and since we strive to deliver the best service possible to our clients, we had to take all possible scenarios into account.
Our main problem was a single point of failure for our infrastructure. Namely, production servers were located on the same physical location, and there were backups of all data stored on secured locations but in case of disaster, it would take hours, even days to bring everything back online, and we didn’t want to take those chances.
So we decided that the best solution to this problem would be to have multiple servers in different locations, and that are in sync with each other.
Building a functional Kubernetes Disaster Recovery on a budget
Building a competitive, enterprise-grade Kubernetes platform requires more than simply deploying your applications. Kubernetes clusters require protection, maintenance, automation, and stability.
Disaster Recovery for Kubernetes can be both time and budget-consuming, but here we will focus on a "budget" Disaster Recovery plan that is mostly based on open-source software, because we wanted to challenge ourselves and see if we can achieve the same results with much smaller expenses.
The software that we are using for our Disaster Recovery strategy is open source, and even though most companies are reluctant to use open source software as Disaster Recovery strategy, our experience is quite positive - open source software is not any "less" secure or stable than most enterprise solutions. In addition to that, it offers more freedom to customize it for your organization's needs. One potential downside is that there won’t be any technical support or guarantee from a large enterprise, but truth be told, if you know what you are doing, these elements are unnecessary and not to mention your company would save a lot of money.
To give you a better insight into dealing with this particular problem, we need to say a few things about infrastructure where this kind of solution was implemented. Targeted infrastructure uses Kubernetes clusters on bare metal machines which gives us full control over our clusters, and production clusters have their own identical replica that is running in separate data centers which allows us to make an easy fail-over if there is any disaster scenario taking place on one of the locations.
Monitoring our systems and notifications in case of disaster is handled by a combination of software that collects metrics regarding our clusters and sends alerts to our company’s Slack channel, email, and even personal smartphones in some cases.
Metric collecting is handled by Prometheus, and Prometheus as a collector does a great job providing metrics to Grafana and Alertmanager. Grafana offers various options that you can use to monitor your infrastructure. Also, it allows you to create your custom dashboards.
For sending alerts and warnings, Alertmanager is one handy tool, and by using metrics collected by Prometheus and a set of custom-defined rules, it will let you know when you are in trouble.
Backups and Data migration
MinIO is the world's fastest object storage server, and a natural fit for companies looking for a consistent, performant, and scalable object store for their hybrid cloud strategies. Kubernetes-native by design, S3 compatible from inception, MinIO has more than 7.7M instances running in AWS, Azure, and GCP today - more than the rest of the private cloud combined. When added to millions of private cloud instances and extensive edge deployments - MinIO is the hybrid cloud leader. Simple, fast, reliable, and open source.
Velero is an open-source tool to safely backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes. Also, it reduces time to recovery in case of infrastructure loss, data corruption, and/or service outages.
Combining MinIO and Velero allows you to sync data between clusters as fast as possible.
Deployment replication
GitLab CI/CD pipeline allows concurrency between deployments, and with the right configuration every pipeline will deploy your applications on multiple clusters at the same time.
Solution
This kind of plan requires minimal human intervention if things go downhill for whatever reason, and as mentioned, the whole strategy is built around reliable, remarkable open-source software.
The diagram below can give you a raw insight into the solution, one live cluster and another replica of the same cluster waiting in standby, just in case.
Gitlab CI/CD deploys the app to the production cluster, Velero takes a backup of stateful data (databases) and stores it on production MinIO cluster, that data is replicated to DR MinIO instance and is then restored using Velero to standby cluster in DR site. You can schedule the Velero backup, MinIO replication, and Velero restore actions according to your RPO/RTO parameters. Since we are using BGP to transfer our public IPs, no further steps are needed. If you don't have that option, you can just change your public DNS records.
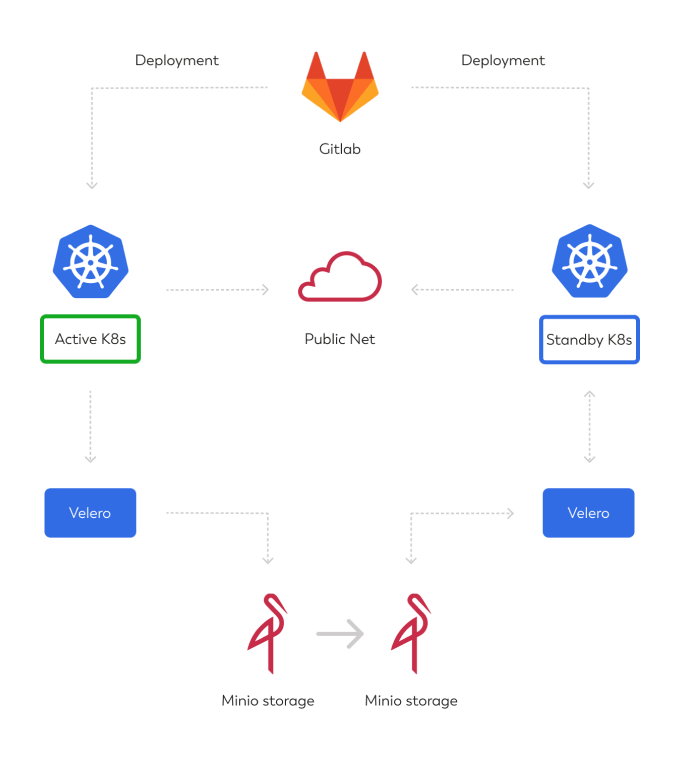
A diagram of Kubernetes disaster recovery plan
Conclusion
In order to comply with the ever changing demands of the business world, most companies take data security seriously to make sure nothing leaks outside of the organization and they don’t lose credibility. However, while a damaged reputation is something a company can rebuild, loss of data at an unexpected moment can put a stop to the entire business, sometimes even for good.
This is why preparing for the unexpected by creating a Disaster Recovery plan is vital to company’s wellbeing - you need to ensure that whatever happens, your business will quickly recover without any significant consequences.
Your take on the subject
They say knowledge has power only if you pass it on - we hope our blog post gave you valuable insight.
If you want to share your opinion or learn more about disaster recovery, feel free to contact us. We'd love to hear what you have to say!